Similar inputs from similar classes should produce similar
representations within the network and should be predicted as
belonging to the same category.
Similarity is based on distance measures which include the
Euclidean distance, dot product and for input vectors from
differing populations, the Mahalanobis distance which is defined
as
where
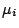 is the mean vector for the population
is the mean vector for the population
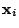 and
and
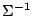 is the inverse of the
covariance matrix
is the inverse of the
covariance matrix